

Python Facebook 爬蟲 簡易案例說明
本篇要說明的不是強大的Facbook爬蟲,而是簡易的案例分享,帶一點點基礎入門
參考連結 :
https://wsvincent.com/install-python3-mac/
http://www.hoamon.info/blog/2007/02/01/pythonpdb.html
1. 安裝python
要可以執行python首先第一步要先在自己的開發機上將python安裝起來
如果你的環境是MAC,那麼應該已經安裝了python 2.7,如果想要使用phthon 3 那麼需要以下步驟來安裝
|
1 2 3 4 5 6 |
#先測試一下版本 python --version ##Python 2.7.10 python3 --version ##Python 3.7.2 |
如果都有出現版本,那麼恭喜你基礎使用環境已經安裝完畢,如果需要安裝python3環境可以參考上面的詳細連結
如果MAC已經安裝了homebrew,那麼只要一行指令即可
|
1 |
brew install python3 |
安裝需要一點時間,可以先倒杯咖啡等一下
2. 安裝所需要的套件
接著,我想列出本次案例有用到的幾個套件
requests、BeautifulSoup、pdb
首先所有的套件都依賴pip來管理,所以必須先安裝pip3 (python3的環境底下)
|
1 2 3 |
brew postinstall python3 pip3 -v #如果指令有找到代表已經成功 |
request套件可以模擬發出http request,來取的遠端URL的內容
BeautifulSoup套件則是用來解析HTML
pdb則是方便用來debug
3. 爬蟲流程
假設今天有一個Facebook 的公開文章,我們想要拿到這篇文章的讚數、留言數、分享數 該怎麼處理?
|
1 2 |
res = requests.get(url) soup = BeautifulSoup(res.text, "lxml") |
首先,用request取得url的內容,透過BeautifulSoup格式化內容
|
1 2 3 4 5 6 7 8 |
likecount = soup.text.split('i18n_reaction_count:') likecount = likecount[1].split(',') if likecount[0] != 'null': likecount = likecount[0].split('"') likes = likecount[1] else: # 為null 沒有人按讚 likes = 0 |
按讚數可以透過”i18n_reaction_count:”來取得,我想要的是”i18n_reaction_count:”後面接的數字
相同概念,留言數以及分享數可以用”i18n_comment_count:”以及”i18n_share_count:”關鍵字來取得
接著,就可以把檔案儲存成.py,透過終端機來執行了
|
1 |
python3 /User/local/getFB.py |
4. python debug的方式
pdb可以協助設定中斷點,舉例來說
|
1 2 3 4 |
url = url.replace("m.facebook.com", "www.facebook.com") res = requests.get(url) pdb.set_trace() soup = BeautifulSoup(res.text, "lxml") |
我們在第三行設定了中斷點,那麼程式執行到第三行就會停下來,像這樣子
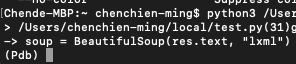
畫面上會停下來進入pdb,並且顯示下一行要執行的程式碼,接下來就可以透過pdb的指令來顯示想要知道的內容
q(quit):離開
p [some variable](print):秀某個變數的值
n(next line):下一行
c(continue):繼續下去
s(step into):進入函式
r(return): 到本函式的return敘述式
l(list):秀出目前所在行號
!: 改變變數的值